Supabase vs CloudKit for a local-first diagnostics app
An early working comparison of Supabase and CloudKit for a private, local-first iPhone diagnostics app. These are provisional findings and product-shape predictions that I want to revisit once the real build, sync path, and browser workflow are exercised.
On this page
14 sectionsStarts closed so you can get straight into the article. Open it if you want the outline.
ExpandCollapse
On this page
14 sectionsStarts closed so you can get straight into the article. Open it if you want the outline.
- The product I actually want to exist
- Why this gets more interesting with the right people around it
- Why CloudKit has a real case
- Where CloudKit starts to feel too narrow
- Why Supabase gets interesting very quickly
- One thing I would watch for enterprise scale
- The source-of-truth decision that matters more than vendor choice
- The experimental predictor angle changes the backend math
- Where Supabase is harder
- My current decision
- The rollout I would actually trust
- Final view
- Further reading
- References
- The product I actually want to exist
- Why this gets more interesting with the right people around it
- Why CloudKit has a real case
- Where CloudKit starts to feel too narrow
- Why Supabase gets interesting very quickly
- One thing I would watch for enterprise scale
- The source-of-truth decision that matters more than vendor choice
- The product I actually want to exist
- Why this gets more interesting with the right people around it
- Why CloudKit has a real case
- Where CloudKit starts to feel too narrow
- Why Supabase gets interesting very quickly
Working thesis
This is not a pitch for a medical-device app, and not a claim that an iPhone can diagnose disease on its own. It is a product design note about building a private personal diagnostics lab: local capture first, selective sync second, and experimental models that stay grounded in longitudinal data, real physiology, and clinical humility.
Experimental note
These are early findings and predictions, not settled conclusions. Some of the argument here is deliberately forward-looking because the full product, sync edge cases, and browser-analysis workflow do not exist yet. I want to circle back and update this piece once those assumptions have been tested against a real build.
I do not want to build another wellness toy.
The thing I actually want to read, use, and keep improving is a local-first personal health diagnostics app: something that can quietly collect meaningful signals, surface patterns worth paying attention to, and eventually support experimental predictors that are interesting enough to test but honest enough not to cosplay certainty.
Once I frame the product that way, the backend question stops being boring infrastructure. It becomes a product question: do I optimize for the cleanest Apple-native sync story, or do I optimize for a future where those signals become queryable, comparable, and research-friendly across iPhone and web?
That is the real Supabase vs CloudKit decision.
The product I actually want to exist
The first version is still iPhone-first and local-first. The phone should work offline, feel immediate, and own the primary write path.
But the ambition is much bigger than "log a few numbers."
I want it to eventually handle things like:
- resting heart rate drift against personal baseline
- heart rate variability trends and recovery windows
- respiratory rate changes
- sleep duration, regularity, and fragmentation
- Apple Health context from movement, workouts, and daily load
- symptom notes, intervention tracking, and adherence
- experimental predictors for "something looks off" versus "you are recovering well"
- browser-based review for long-horizon trends, exports, and research-style analysis
That is already the shape of a longitudinal diagnostics system, not a single-screen tracker. Digital biomarker work gets interesting exactly when multiple weak signals start becoming more useful together than they are on their own.
Refs1-3Why this gets more interesting with the right people around it
A big reason I am excited about this direction is that I am not thinking about it alone.
My partner is a doctor with cardiothoracic experience, a master's in cancer research, and a bachelor's in microbiology. That is an unusually good companion for this kind of product because the conversation immediately gets sharper.
The question stops being "wouldn't it be cool if the app predicted something?" and becomes:
- which metrics are actually credible versus decorative
- which outputs should stay hypothesis-generating instead of sounding diagnostic
- which interventions are measurable enough to test
- where ML might help detect signal
- where clinical judgment should clearly remain in charge
That is the kind of tension I want. It keeps the product honest.
Why CloudKit has a real case
If this were only about a private iPhone app, CloudKit would be hard to argue against.
CloudKit fits the Apple worldview well:
- native Apple infrastructure
- strong alignment with iPhone-first privacy expectations
- natural fit for per-user private data
- less backend plumbing to stand up on day one
If the app were mostly "capture on iPhone, review on iPhone, maybe sync across Apple devices," I would be very happy to lean into CloudKit and let Apple carry more of the sync story. Apple already gives me the device-level health data surface through HealthKit, and their sync stack is designed around exactly this sort of Apple-native continuity.
Refs9-11That is the cleanest version of the CloudKit argument: keep the system Apple-shaped, keep the first version small, and delay backend complexity until there is proof the product deserves it.
Where CloudKit starts to feel too narrow
The problem is that I do not actually want an Apple-only product shape.
I want a browser companion that can do things the phone should not have to do well:
- inspect long-run trends across months or years
- compare predictors against eventual outcomes
- export clean tables for experiments
- audit what a model saw before it made a suggestion
- create clinician-friendly summaries instead of raw app screens
- support future research workflows without rebuilding the storage layer later
That is where CloudKit starts to feel like the elegant near-term answer and the awkward long-term one.
It is not that CloudKit is bad. It is that once the product becomes "personal diagnostics plus experimental predictor lab," browser access and relational querying stop being nice-to-haves. They become part of the product.
Why Supabase gets interesting very quickly
Supabase is attractive because it turns the hosted layer into an actual product surface instead of a pile of custom backend chores.
What I get immediately is a combination that maps cleanly to the product I am describing:
- Postgres for structured longitudinal health records
- Auth for controlled access
- Row Level Security for per-user data boundaries
- Realtime for selective sync and presence-like feedback
- Storage for exports and attachments
- first-party Swift support through
supabase-swift - a web-friendly query layer from day one
That matters because a diagnostics-oriented app wants more than raw sync. It wants queryability. It wants clean relational history. It wants views, derived tables, reproducible experiments, and a place where future ML features can plug into the same source of truth. Supabase is not magic, but it is unusually well-matched to that shape.
Refs4-8The more I think about experimental predictors, the more I want the backend to look like a research notebook with guardrails instead of a black box.
One thing I would watch for enterprise scale
This does not change my near-term product call, but there is one adjacent Postgres development I would keep an eye on for larger rollout questions: OrioleDB.
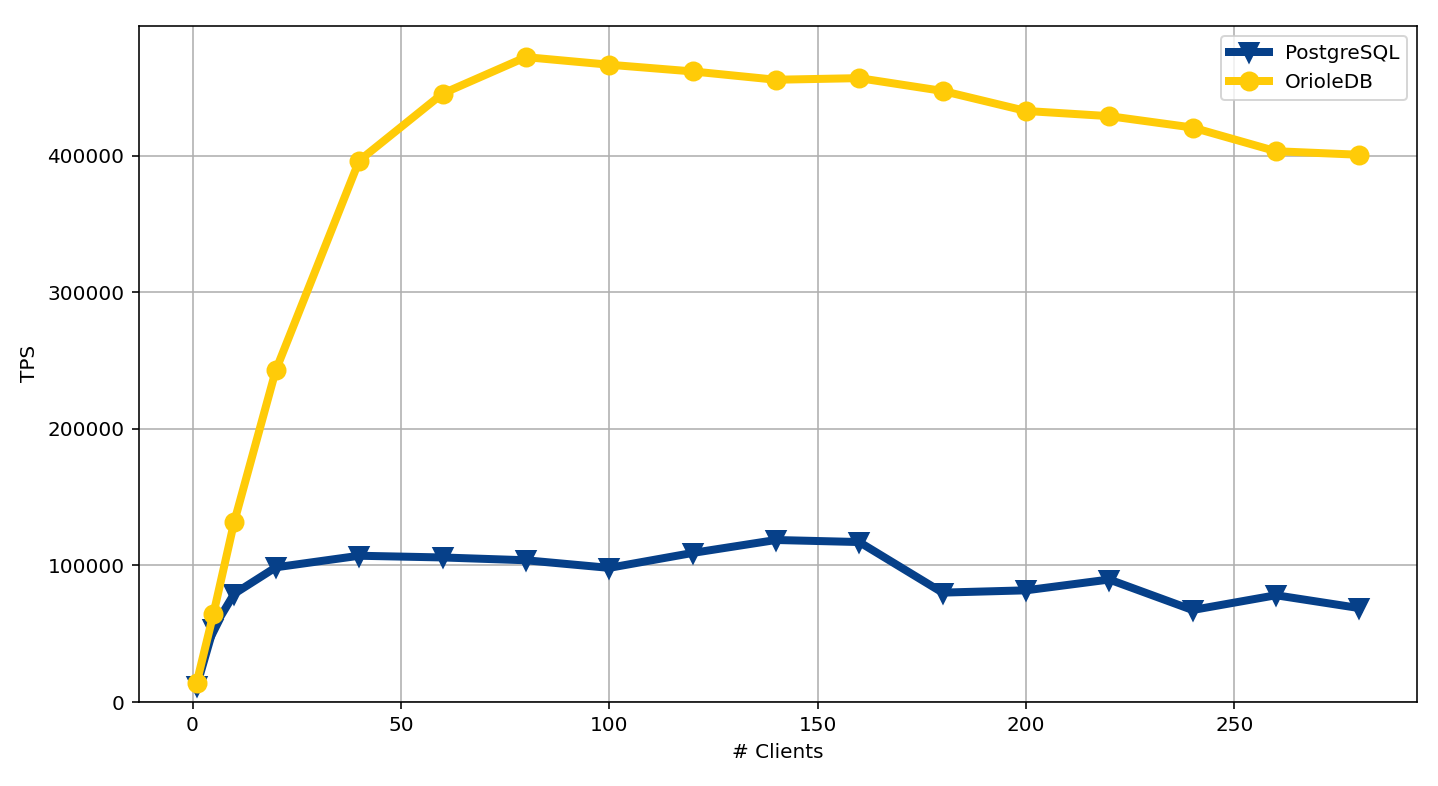
One reason it is worth watching: OrioleDB’s own homepage benchmarks show markedly different read-write scaling under higher client counts. I read this as a signal to monitor, not as a basis for today’s architecture choice. Source: OrioleDB homepage.
Why it is interesting is not hype-by-association. It is the shape of the bet. OrioleDB positions itself as a PostgreSQL storage engine built for modern hardware, with copy-on-write checkpoints, row-level WAL, undo-log-based MVCC, and lower maintenance overhead than the traditional bloat-and-vacuum story. If that family of ideas matures in the ecosystem, it is relevant to the kind of enterprise question that shows up later: how comfortably does the stack scale when the workload becomes more concurrent, more write-heavy, and more operationally expensive to babysit?
Refs12That is not a reason to pick Supabase today, and definitely not a reason to pretend an early personal diagnostics app has enterprise-scale problems already. It is just a useful thing to watch if the product ever needs to graduate from a careful local-first tool into a more serious multi-tenant or organization-facing system.
It is also worth keeping the current limitations in view: OrioleDB’s docs still describe the project as being in the
development stage, with some unsupported or experimental areas today, including SERIALIZABLE isolation and some
non-btree index support. Refs13
The source-of-truth decision that matters more than vendor choice
The architecture I keep coming back to is simple:
- the iPhone app remains the primary write client
- the on-device SQLite store stays canonical for immediate user actions
- sync happens outwards from the phone instead of making the network a prerequisite
- the hosted database becomes the shared longitudinal query layer
- the web app begins read-only and analytical before it ever tries to become a second write surface
That keeps the product local-first in the only way that actually counts: the phone remains useful when the network disappears, and the person holding the data still feels like they own the system.
Supabase works well in that setup because Postgres becomes the synchronized analysis surface, not the place where every tap has to round-trip before the UI can move.
The experimental predictor angle changes the backend math
This is the part that makes the decision much more fun.
If the app eventually starts exploring predictors, I do not just want to ask "can I sync records?" I want to ask questions like:
- do baseline shifts in resting heart rate plus sleep fragmentation predict a rough week ahead
- do respiratory changes plus symptom notes deserve a flag
- do certain intervention patterns correlate with better recovery
- can longitudinal combinations outperform any single metric
- can I explain those outputs cleanly enough that a skeptical grown-up would still read them
That is not a CloudKit-shaped wish list. That is a SQL-and-experiments wish list.
A managed Postgres layer makes it much easier to create derived features, run browser-based inspections, expose safe read models, and eventually support lightweight ML services without first escaping an Apple-specific storage story. Even the more interesting digital biomarker results are heading in that direction: the useful work tends to come from combining wearable or passive signals with careful modeling, not from glorified step counts. Refs1-3
Where Supabase is harder
The trade needs to stay honest.
Supabase buys flexibility by making me own more of the system earlier:
- sync contracts
- conflict handling
- retries and offline queues
- security policy design
- compliance posture and data governance
- more deliberate schema evolution
CloudKit is attractive partly because it delays that responsibility.
So the real trade is not "simple versus complex." It is this:
| Question | CloudKit | Supabase |
|---|---|---|
| Fastest path to a pure Apple app | Strong | Good, but more setup |
| Browser companion later | Awkward | Native to the shape |
| Longitudinal querying and exports | Limited ergonomics | Excellent |
| Experimental ML or derived feature work | Possible, but indirect | Much cleaner |
| Privacy boundaries | Apple-native | Explicit with RLS |
| Operational responsibility | Lower early | Higher early |
For the product I actually want, those tradeoffs point in one direction.
My current decision
This is a working call, not a permanent verdict.
If I were starting this build right now, I would choose Supabase first.
Not because CloudKit is weak. Not because every iOS app secretly wants Postgres. Because I am no longer pretending the browser is a vague someday nice-to-have.
The real product is:
- private and local-first on the phone
- syncable across a tiny trusted group at first
- queryable on the web
- structured enough for longitudinal health analysis
- careful enough to keep "prediction" subordinate to evidence
That stack looks a lot more like local SQLite plus Supabase than local SQLite plus CloudKit.
The rollout I would actually trust
I would still build it in a disciplined order instead of trying to look clever too early.
- Make the iPhone app excellent offline.
- Lock down the local schema around signals, baselines, notes, and interventions.
- Ship a tiny real-world beta with just enough sync to validate the data model.
- Keep the web layer read-only at first.
- Add derived tables and dashboards only after the raw signal model stops changing every week.
- Introduce experimental predictors only when the logged data is rich enough to make the exercise honest.
That sequence matters. The fastest way to ruin a product like this is to bolt ML language onto a thin dataset and mistake novelty for signal.
Final view
Treat this as a provisional architecture note rather than a final scorecard.
CloudKit is the better default for a private Apple-native app that mostly wants to stay inside Apple's walls.
Supabase is the better default for a local-first personal diagnostics product that wants to grow into a serious longitudinal data system.
That is why this choice got more exciting for me. It is not really a storage argument anymore. It is a bet on what kind of product this wants to become.
If the real build proves some of these assumptions wrong, this is exactly the sort of post that should be revised, not defended out of pride.
I do not want another dashboard.
I want something that can earn the right to notice, remember, compare, and eventually say: this pattern is worth a closer look.
Further reading
- Supabase documentation
- Supabase Swift reference
- Supabase Row Level Security guide
- Supabase Realtime guide
- supabase-swift on GitHub
- CKSyncEngine documentation
- Syncing model data across a person's devices
- HealthKit workouts and activity rings
- OrioleDB architecture overview
References
- Vasudevan S, Saha A, Tarver ME, Patel B. Digital biomarkers: Convergence of digital health technologies and biomarkers. npj Digital Medicine. 2022;5:36.
- Daniore P, Nittas V, Haag C, et al. From wearable sensor data to digital biomarker development: ten lessons learned and a framework proposal. npj Digital Medicine. 2024;7:161.
- Huang X, Schmelter F, Seitzer C, et al. Digital biomarkers for interstitial glucose prediction in healthy individuals using wearables and machine learning. Scientific Reports. 2025;15:30164.
- Supabase. Supabase Docs.
- Supabase. Supabase Swift reference.
- Supabase. Row Level Security.
- Supabase. Realtime.
- Supabase. supabase-swift.
- Apple. CKSyncEngine.
- Apple. Syncing model data across a person's devices.
- Apple. HealthKit: Workouts and activity rings.
- OrioleDB. Architecture overview.
- OrioleDB. Usage and current limitations.
Related entries
Setgraph, Apple Health, TabPFN, and the day my lifting log got serious
I pulled my Setgraph history and Apple Health context into one table, rebuilt 1,548 exercise-sessions, benchmarked six tabular models, and learned three things fast: completed session quality was more explainable than I expected, cardio 24-48 hours before lifting looked better than expected, and personal-record windows were narrower than normal training defaults.